Attention Is All You Need
The paper that started the AI revolution.
What Problem Are We Solving?
Imagine you're Google Translate. Someone types a sentence in English and wants it in Hindi. The sentence has an order — words depend on each other. "The bank of the river" and "I went to the bank" use the same word "bank" but mean completely different things.
The task of converting one sequence (English) to another sequence (Hindi) is called Sequence-to-Sequence (Seq2Seq) — and before 2017, this was done using RNNs and LSTMs. They worked… but had serious problems.
Think of reading a book vs. looking at a painting. An RNN reads a book word-by-word, left to right — if the answer to a question was on page 1 and you're on page 300, you've probably forgotten it. A Transformer is like looking at a painting — you see EVERYTHING at once and decide what's important.
RNN — The Assembly Line Worker
A Recurrent Neural Network (RNN) processes sequences one step at a time. It reads word 1, creates a "memory" (hidden state), then reads word 2 while carrying the memory forward, and so on.
Imagine a game of Telephone (Chinese Whispers). Person 1 whispers a message to Person 2, who whispers to Person 3… By Person 20, the original message is totally misinterpreted. That's exactly what happens to information in a long RNN — the early words get "forgotten."
1. Sequential = Slow: Word 5 MUST wait for Words 1-4 to finish. You can't use all your GPU cores at once.
2. Vanishing Gradient: In long sentences, the model forgets early words. The signal fades like a weak phone signal over distance.
3. No long-range memory: "The cat, which sat on the mat and played with the yarn and ate the fish, was happy" — the RNN has trouble connecting "cat" with "was" because they're so far apart.
LSTM — The Improved Worker (Still Too Slow)
Long Short-Term Memory (LSTM) networks were invented to fix RNN's forgetting problem. They add special "gates" — like a valve system — that decide what to remember and what to forget.
LSTM is like a student with a notebook. An RNN tries to remember everything in its head (and fails). An LSTM writes important stuff in a notebook (cell state). The forget gate = erasing old notes. The input gate = writing new notes. The output gate = deciding which notes to look at now.
LSTMs are better at remembering, but they're STILL sequential. Word 100 still has to wait for words 1–99 to process. Training on millions of sentences takes forever. And for very long documents, even LSTMs start to forget.
RNN
❌ Forgets early words
❌ Very slow (sequential)
❌ Can't handle long text
LSTM
✅ Better memory
❌ Still slow (sequential)
❌ Complex, hard to train
Transformer
✅ Sees all words at once
✅ Massively parallel = fast
✅ Handles any length
What is Attention?
Attention is a simple but powerful idea: not all words are equally important. When translating a sentence, you should "pay attention" to the relevant words, not all of them equally.
You're at a noisy party. 50 people are talking. But when your friend says your name, you instantly "attend" to their voice and tune out everything else. THAT is attention — the ability to focus on what matters and ignore the rest.
In technical terms, attention works with three things:
Query (Q) — "What am I looking for?"
Like a search query on Google. The current word asks: "Hey, who should I pay attention to?"
Key (K) — "What do I contain?"
Like the title of each webpage. Every other word advertises: "Here's what I'm about."
Value (V) — "Here's my actual content"
Like the actual webpage content. Once you've found a match, you grab the value.
You type "best pizza near me" (that's your Query). Google looks at every webpage's title/keywords (the Keys). It finds matches, ranks them by relevance, and shows you the actual page content (the Values). The higher the match between your Query and a Key, the more attention that result gets.
Step 1 (Q × Kᵀ): Check how similar each Query is to each Key — like comparing your exam question with every chapter title.
Step 2 (÷ √dₖ): Scale the scores down so they're not too huge (prevents math from exploding).
Step 3 (softmax): Convert scores into percentages that add to 100%. Now you know exactly how much attention to give each word.
Step 4 (× V): Use those percentages to grab a weighted mix of the actual content from each word.
Softmax converts any list of numbers into percentages that add up to 100%. It takes raw scores (which can be anything — negative, positive, huge, tiny) and turns them into a clean percentage distribution where the biggest score gets the biggest slice.
The formula: softmax(xᵢ) = eˣⁱ / Σ eˣʲ. Think of eˣ as a "stretcher" — it does two things: it makes every number positive, and it exaggerates the gaps. A score that's only slightly higher than the rest ends up with a much bigger share.
Concrete example. Say attention scores for 3 words are [2.0, 1.0, 0.1]. Softmax gives roughly [0.66, 0.24, 0.10] — so the model pays 66% attention to word 1, 24% to word 2, and just 10% to word 3. Total = 100%. This is what lets us blend words together in a meaningful, weighted way.
Why not just divide each score by the total? Two problems: negative numbers would break plain division, and you want the top score to really stand out — not just win by a little. Softmax makes the strongest signal dominate, while still keeping every word in the mix (nothing ever gets a hard zero).
dₖ is simply the size (length) of each Key vector. Q, K, and V aren't single numbers — they're lists of numbers called vectors. In the original paper, each word's Key is a list of 64 numbers, so dₖ = 64. The Query is the same length so that multiplying Q × K actually works.
The problem without scaling. When you multiply two vectors together (dot product), the result gets bigger as the vectors get longer — because you're adding up more numbers. With dₖ = 64, some scores can shoot up into the tens or hundreds.
Why that breaks softmax. Feed huge numbers into softmax and one score completely beats the rest — you get something like [0.9999, 0.0001, 0, 0, …] instead of a healthy spread. This is called saturation
The fix. Dividing by √dₖ brings the scores back down to a reasonable range, no matter how long the vectors are. Softmax then produces soft, spread-out distributions like [0.5, 0.3, 0.2] instead of [1, 0, 0].
Self-Attention — Words Talking to Each Other
Regular attention is when the decoder looks at the encoder (translating English → Hindi, Hindi words look at English words). Self-attention is when words in the SAME sentence look at EACH OTHER.
Imagine a classroom of students. In regular attention, the teacher (decoder) looks at students (encoder) to understand them. In self-attention, students look at each other to understand context. When someone says "she," every student looks around to figure out who "she" refers to.
Consider the sentence: "The animal didn't cross the street because it was too tired."
What does "it" refer to? The animal or the street? Self-attention figures this out by letting "it" look at every other word and discovering that "animal" is the most relevant match.
This is magical. Without anyone explicitly programming grammar rules, the model learns by itself that "it" refers to "animal." This is why it's called self-attention: the sentence attends to itself.
Multi-Head Attention — Looking from Many Angles
Single attention is great, but one perspective isn't enough. What if you need to understand grammar and meaning sentiment at the same time? That's where Multi-Head Attention comes in.
Imagine 8 detectives investigating a crime scene. One detective focuses on fingerprints, another on footprints, one on motive, one on alibis, etc. They each find different clues. At the end, they combine all their findings into one complete report. That's multi-head attention — 8 parallel attention "heads," each learning to focus on different things.
The paper uses 8 heads. Each head gets a smaller slice of the data (512 ÷ 8 = 64 dimensions each), runs its own attention, and then all 8 outputs are concatenated and projected back to the full size. The computation cost is the same as single-head attention, but the understanding is much richer.
The Transformer — The Full Architecture
Now we put it all together. The Transformer has two halves: an Encoder (reads the input) and a Decoder (generates the output). Both are built from stacked layers, each containing attention and feed-forward networks.
The Encoder is like a reader who reads an English book thoroughly and creates detailed notes. The Decoder is like a writer who reads those notes and writes the Hindi translation word-by-word, constantly referring back to the notes.
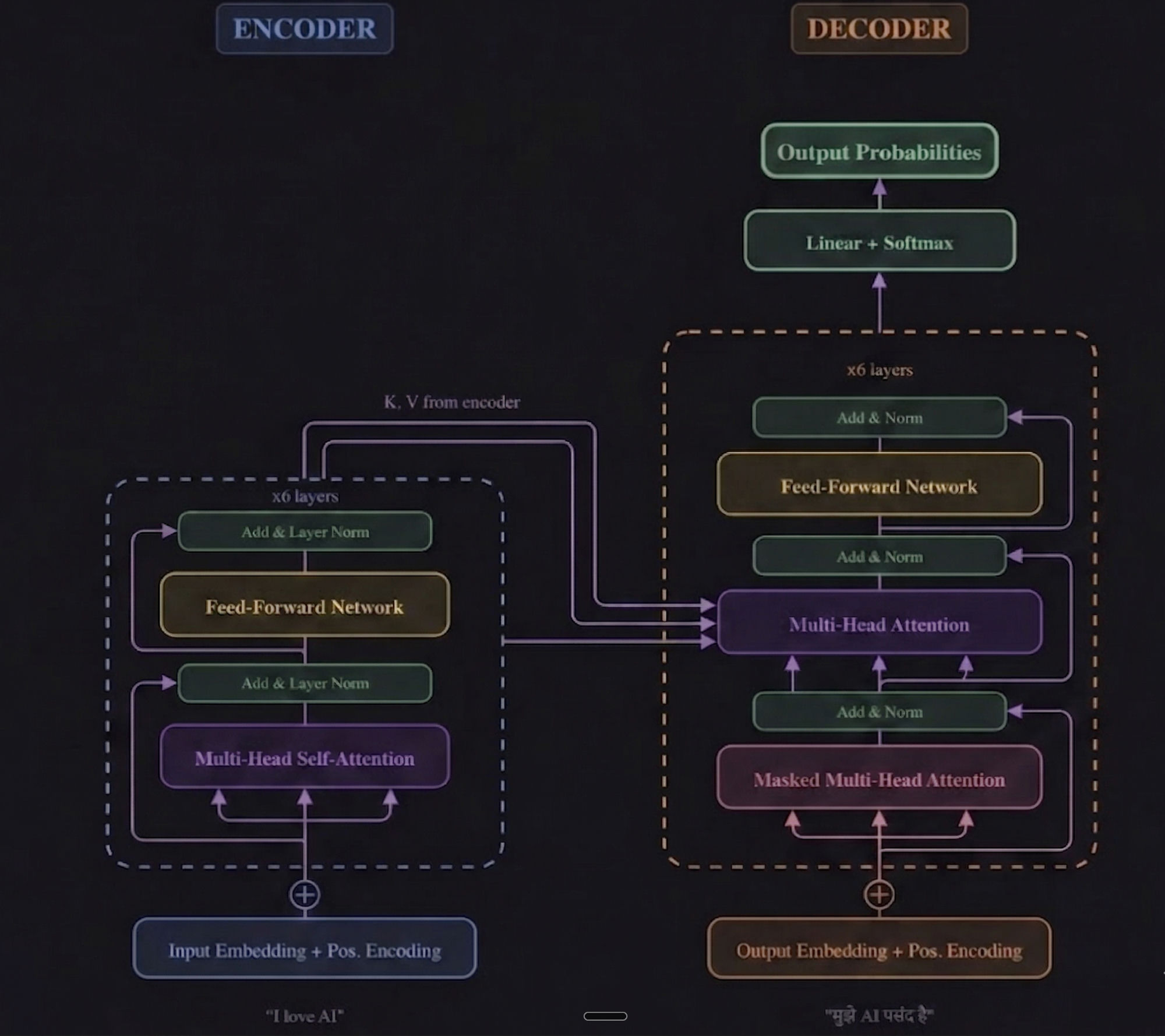
Breaking Down Each Component:
Input Embedding
Converts each word into a vector of 512 numbers. "Cat" becomes [0.23, -0.87, 1.2, ...]. Think of it as giving each word a unique GPS coordinate in 512-dimensional space.
Positional Encoding
Since the Transformer sees all words at once (not sequentially), we add position info using sine/cosine waves, so the model knows which word came first, second, third, and so on.
Encoder Stack (×6 layers)
The encoder's job is simple: read the input sentence and build a rich understanding of it. Each of the 6 layers does the same thing twice — first the words look at each other (self-attention) to figure out context, then each word is passed through a small neural network (feed-forward) that refines its meaning. After each step, "Add & Normalize" keeps the numbers stable so training doesn't blow up. Think of it like 6 rounds of re-reading: each round the model understands the sentence a little better. The final output is a set of "smart vectors" — one per input word — that the decoder will use.
Decoder Stack (×6 layers)
The decoder generates the output one word at a time. Each layer has three sub-steps:
(1) Masked Self-Attention — the decoder looks at the words it has already written so far, but is not allowed to peek at future words. Why? Because during training, the full target sentence is fed in at once, and without the "mask," the model would cheat by looking ahead at the answer. The mask hides future positions so each word only sees the past — exactly how it will work at prediction time.
(2) Cross-Attention — the decoder looks at the encoder's output (the "smart vectors" from the input sentence) to decide which input words matter most for the word it's about to write.
(3) Feed-Forward Network — a small 2-layer neural network applied to each position independently. It takes the attention output and runs it through Linear → ReLU → Linear, giving the model extra "thinking power" to transform the information before passing it to the next layer.
What does Linear → ReLU → Linear actually mean? Imagine each word's vector (512 numbers) as a row of dials.
Linear = a big mixer. It takes all 512 dials and combines them into 2048 new dials, where each new dial is a weighted mix of the old ones (like making 2048 different smoothies from 512 ingredients). It expands the space so the model has more room to think.
ReLU = a simple on/off filter. For every dial, if the number is negative it becomes 0; if it's positive it stays as it is. This is what lets the network learn non-linear patterns — without it, stacking layers would be the same as having just one layer. ReLU is what makes deep networks actually "deep."
Linear (again) = another mixer that shrinks those 2048 dials back down to 512, so the output matches the input size and can flow into the next layer. Net effect: the model briefly expands each word into a bigger space, filters out the noise, then compresses it back — a quick "think harder about this word" step.
Add & Layer Norm (Residual Connections)
Like a safety net — the original input is added back to the attention output. If attention learns nothing useful, the original signal still passes through. Prevents information loss.
Final Linear + Softmax
Converts the decoder output into probabilities over the entire vocabulary. If the vocabulary has 37,000 words, it gives a probability for each one. The highest probability wins!
The Encoder is like a book club — 6 rounds of discussion where members keep re-reading and discussing the input text, each round building deeper understanding. The Decoder is like a translator writing a draft — also 6 rounds, where they look at their own writing so far (masked self-attention), check the book club's notes (cross-attention), and refine each word.
Walkthrough: How Does a Transformer Actually Answer a Question?
Let's trace exactly what happens inside a Transformer when you type "What is 2+2?" and it responds "2+2 is 4". This is the same process behind every ChatGPT reply, every code completion, every AI translation.
Step 1 — Encode the Input
The encoder reads all input tokens at once: ["What", "is", "2", "+", "2", "?"]. Each word is converted into a 512-number vector (embedding), position info is added, and then 6 encoder layers process them in parallel. Self-attention lets "2" and "+" look at each other to understand "this is an addition." The output is 6 "smart vectors" — one per token — packed with context.
Step 2 — Decoder Starts with <START>
The decoder begins with a single special token: ["<START>"]. It runs masked self-attention (only one token, so nothing to mask yet), then cross-attention looks at the encoder's smart vectors and asks: "Given this math question, what should the first output word be?" The final softmax layer produces probabilities over the entire vocabulary — and "2" wins with the highest probability.
Step 3 — Feed "2" Back In, Predict Next
Now the decoder input is ["<START>", "2"]. Masked self-attention lets "2" look at <START> but not ahead. Cross-attention checks the encoder output again. The model predicts "+" as the next token.
Step 4 — Feed "+" Back In, Predict Next
Decoder input: ["<START>", "2", "+"]. Same process — self-attention across existing tokens, cross-attention to the encoder. Predicts "2".
Step 5 — Continue the Cycle
Input: ["<START>", "2", "+", "2"] → predicts "is".
Input: ["<START>", "2", "+", "2", "is"] → predicts "4".
Input: ["<START>", "2", "+", "2", "is", "4"] → predicts <END>. Done!
This is called autoregressive generation. The Transformer doesn't spit out the entire answer at once — it predicts one token at a time, feeding each prediction back as input for the next. The encoder runs once (it already understood the question), but the decoder runs once per output token. This is why longer responses take longer to generate — each word is a full pass through all 6 decoder layers.
This same loop powers everything: ChatGPT writing an essay (one word at a time), Copilot completing your code (one token at a time), a translation model converting English to Hindi (one word at a time). The magic of the Transformer is that despite generating sequentially, every step uses parallel attention over all previous tokens — so it never forgets and never slows down the way RNNs did.
Training & Results
The Transformer was trained on English-to-German and English-to-French translation tasks. Here's what makes it remarkable:
Training Setup
8 NVIDIA P100 GPUs
Base model: 12 hours training
Big model: 3.5 days training
4.5M sentence pairs (EN-DE)
Results
EN→DE: 28.4 BLEU (new record)
EN→FR: 41.0 BLEU (new record)
Trained in a fraction of the time
Beat ALL previous models
Remember, RNNs process words one by one. If a sentence has 50 words, that's 50 sequential steps. The Transformer processes all 50 words simultaneously. It's like having 50 workers doing their tasks in parallel vs. one worker doing 50 tasks in a row. The GPU's thousands of cores are finally being used to their full potential.
Why This Paper Changed Everything
This 2017 paper didn't just improve translation. It gave birth to the entire modern AI landscape:
2017 — Transformer is born
"Attention Is All You Need" published at NeurIPS
2018 — BERT (Google)
Encoder-only Transformer → revolutionized search & NLP
2018–2020 — GPT-1, GPT-2, GPT-3 (OpenAI)
Decoder-only Transformer → showed language models can generate text
2020 — Vision Transformer (ViT)
Transformers for images, not just text!
2022–2025 — ChatGPT, Claude, Gemini, etc.
The entire generative AI revolution — ALL built on Transformers
Every AI you use today — ChatGPT, Claude, Google's search, Siri, Alexa, GitHub Copilot, DALL·E, Midjourney — traces its DNA back to this single paper. The 8 authors fundamentally changed computing forever, and the key insight was beautifully simple: stop processing words one-by-one. Let every word look at every other word, all at once.
The Full Journey in 60 Seconds
RNNs read text word-by-word → slow & forgetful
Like a game of telephone — info gets lost over long sequences.
LSTMs added gates to remember better → still slow
Like giving the telephone player a notebook — better memory, same speed problem.
Attention lets models focus on relevant words
Like being able to look back at any part of the message instead of relying on the last whisper.
Self-Attention lets words in the same sentence understand each other
"It" learns that "it" refers to "animal" by looking at all words simultaneously.
Multi-Head Attention adds 8 parallel perspectives
8 detectives each finding different patterns, combining their findings.
The Transformer stacks all of this into an Encoder + Decoder
Processes everything in parallel. Faster training, better results. Game over for RNNs.